A few days ago Y Combinator published its Summer 2026 Requests for Startups. Tom Blomfield, one of the partners, named a pattern that has been visible to operators for at least a year and gave it an official label: the Company Brain.
His description: a system that pulls knowledge out of every fragmented source, structures it, keeps it current, and turns it into an executable skills file for AI. Not a search tool. Not a chatbot over documents. A living map of how a company actually works, designed so that AI agents can do the work safely and consistently. He believes every company in the world is going to need one. You can read his full framing in the YC RFS write-up and in Linas Beliūnas’s summary of the dominant themes.
The reason that framing matters is that several builders had already arrived at the same architecture from different angles. The pattern is not new. The label is. And once a label exists, the conversation gets a lot easier.
This piece is a tour of those builders, the architecture they all converge on, the version I have been quietly building since Andrej Karpathy’s original second-brain post, and the real hurdles I have hit installing pieces of it inside other companies through Claude Teams engagements over the last few months.
I am not finished. The system is not finished (will it ever be?)
What follows is what I have learned from each of them and what is still hard.
Jump to: Karpathy · Garry Tan · Hannah Stulberg · Ramp · The pattern · Where I’ve got to with AFCS · What’s hard inside companies · Why this is antifragile
The framing: autopilot, not autonomy
I keep coming back to one analogy because it has held up under pressure for a while now. A real autopilot does not fly the plane. It holds the course you set, adjusts for turbulence, reads instruments faster than you can, and frees you to think about where you are actually going.
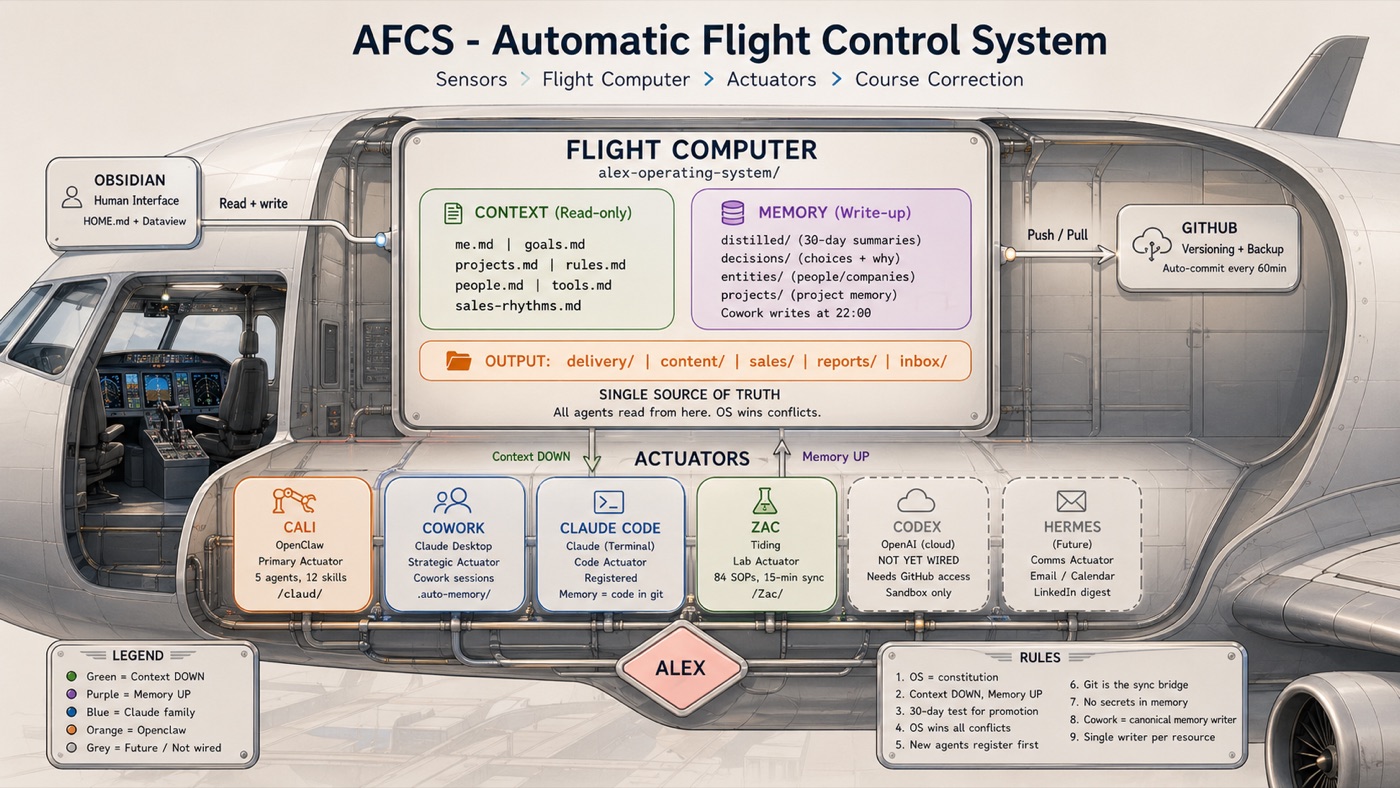
That is what the AFCS is. Automatic Flight Control System. Not because it replaces me, but because it does for business operations what autopilot does for pilots. Sensors read the environment. A flight computer processes the data. Actuators take action. A feedback loop course-corrects. The pilot still flies. The system holds the course.
The hero image at the top of this piece is the mapping. Sensors are inputs - I am the principal sensor. Email, meetings, curated content (human pattern spotting, sentiment); the things I notice and interact with feed in. Flight computer is the substrate. Wiki, entities, skills, resolver. Actuators are the tools. Interchangeable. Outputs are drafts, briefings, posts, call prep, business artefacts and I’d include automated workflows here too. Feedback loop is the filed-back habit. Outcomes go back into the wiki and every loop is smarter.
If you only take one image away from this piece, I would rather it was that one. The Company Brain is autopilot. Not autonomy.
Part 1: The four builders
Karpathy started it
I want to be clear about provenance before anything else. I did not arrive at this pattern independently. Andrej Karpathy posted about his “wiki of markdown files” workflow last year. A large fraction of his recent token throughput, he said, was going not into manipulating code but into manipulating knowledge. He dumps raw sources into a folder. An LLM organises them into structured markdown. He asks questions against the wiki. He files the answers back in. Each question makes the wiki smarter. He called the whole thing a hacky collection of scripts, and added that there is room for an incredible new product here.
That post is when I started building. I wrote up my first version a few weeks ago in How I Built a Second Brain That Builds Itself. The architecture there is the Karpathy pattern with operating-context dropped in: I am not a researcher, I run four businesses, and the problem I face is operational, not academic. But the bones came directly from Karpathy. The compounding insight, the markdown-files-not-database choice, the “answer is also knowledge, file it back” loop. All his.
What Karpathy gave me, specifically, that is still load-bearing in AFCS today: the discipline of treating every answer as new knowledge worth filing. It sounds obvious. It is not. Most AI tools throw the answer at you and forget it. Karpathy’s insight was that the answer is the most refined data in the system. It would be insane to throw it away. The wiki compiler I run nightly only exists because of that one sentence in his post.
Since then three more reference points have appeared, and they all rhyme.

Garry Tan: resolvers as management
In April, Y Combinator’s CEO Garry Tan open-sourced his agent architecture. He calls it GBrain (the knowledge layer) and GStack (the skills layer, currently sitting on more than seventy thousand GitHub stars). What stood out was not the code, it was the discipline around it.
GBrain ships with a RESOLVER.md at the root that routes natural-language queries to the right place in the repo. It ships with explicit filing rules so skills cannot misfile to the brain. And it ships with a meta-skill called check-resolvable, a weekly audit that walks the resolver to make sure no skill has gone dark. Tan’s first run found that fifteen percent of the system’s capabilities were unreachable.
His framing: resolvers are management, not code. An agent system with forty skills is an organisation that needs an org chart, performance reviews and compliance audits. That language is the bridge. It is the moment the conversation stops being about “AI tools” and starts being about operating models.
What Tan gave me, specifically: the routing layer. My AFCS had skills, but no formal RESOLVER.md. Skills were discoverable through directory structure and a vague docs index. After Tan, I added a single canonical RESOLVER.md with one row per skill or scheduled task and a maintainer rule that any new skill or task adds a row in the same change. Within two weeks the dark-capability problem was solved. Things I had built and then forgotten resurfaced. The weekly filing-lint pass I run is the same instinct as check-resolvable. Tan made the system inspectable in a way it was not before.
Hannah Stulberg: Team OS at DoorDash
A few days ago Hannah Stulberg posted on LinkedIn about a system she calls the Team OS. She is a product manager at DoorDash, formerly at Google. She walked Aakash Gupta through her live setup in a deep-dive video (also available as a starter repo).
The Team OS is a shared GitHub repo where product, design, analytics and engineering all check in their work. Customer call summaries. Metric definitions. SQL queries. PRDs. Bug investigations. Competitive research. All of it structured so that any coding agent can find the right context for any team member doing any task.
The proof point she leads with is not a productivity number. It is that her non-technical strategy and operations partner, who had never opened GitHub two months ago, now puts up pull requests every single day. Every customer call she takes goes into the repo. The whole team can review what was learned.
Stulberg has put fifteen hundred hours into Claude Code and is, in her words, still iterating on her setup every single day. The phrase that landed in Avinash Ahuja’s reply under her post sums up why this matters: “That’s less a tooling story and more an operating model story.”
What Stulberg gave me, specifically: the realisation that AFCS was too operator-shaped. I had built it for me. The system worked because I knew where everything was. Anyone else stepping in would have hit a wall. Stulberg’s strategy partner doing daily PRs is the proof that the substrate has to be usable by someone who has never seen the architecture document. The role-shaped briefings I now generate (sales, content, ops, general) are a direct response. They are the entry point for someone who is not me. Without them the system is a private tool. With them it can be a team layer.
Ramp: Glass and Dojo
The fourth example is a company, not a person. Ramp’s internal Glass system (with its skills marketplace called Dojo) runs on the same logic at company scale. Three hundred and fifty plus shared skills, each one a piece of structured context that any operator inside the company can call.
What Ramp adds to the picture is the idea that the skills are the product of the enablement, not separate to it. The act of writing a skill is how the company learns. Onboarding gets easier because the new hire is reading the same skills the system uses. The system gets smarter because the new hire writes new skills as they learn. The same artefact serves both audiences, which is unusual and load-bearing.
What Ramp gave me, specifically: the productisation roadmap. AFCS today is a single-operator system. Ramp’s Glass is the same shape at company scale, with a skills marketplace as the social layer. That is the next step for what I am building. I do not need three hundred and fifty skills. I need the seed library, a contribution model, and a way to ship the substrate into another business without it being a custom build every time. That is in the 2026 roadmap and it is named directly after Glass.
The pattern itself

Strip away the names and the audiences and the same five things appear every time.
A central, structured store. Markdown in a git repo or a folder. Plain text that humans and machines can both read. Not a SaaS database. Not a wiki product. The substrate is portable on purpose.
A routing layer. A RESOLVER.md, a doc index, a CLAUDE.md (or AGENTS.md) at the root that loads on every session. The agent has to know where things live before it can use what is there. Stulberg’s post specifically calls this out as the unlock for natural-language queries like “Slack Alex about the bug from today’s customer call”.
Skills as the unit of work. Self-contained, callable, version-controlled. Not chat templates. Actual capabilities that compound. Tan’s GStack, Ramp’s Dojo and Stulberg’s Claude folder are all the same shape.
A discipline of writing things back. Karpathy files his answers back in. Stulberg’s strategy partner checks in every customer call. Tan runs check-resolvable weekly. Ramp’s skills evolve through use. The compounding is not magic. It is the habit.
A separation of context from compute. The model changes every six months. The substrate does not. You can swap Claude for the next thing without losing your wiki. You cannot swap your wiki without losing your business memory.
That last point is the one that decides whether you are building a system or buying a tool.
Part 2: My version
Where I have got to with AFCS
Mine started, as I said, the day Karpathy posted. It has been running long enough now to call out what has worked, what has not, and what is next. I am building what I need, not what would impress someone. Anything in here that exists is because a real problem hit me on a real Tuesday and I needed an answer.

What is built today.
A wiki compiler that runs daily, pulling raw notes, meeting transcripts, email summaries, market signals and decisions into a compiled knowledge base across six domains: operations, sales, content, market, people and technical. This is the Karpathy layer.
Role-specific morning briefings. Sales sees pipeline, deals, outreach, prospecting. Content sees performance, audience, positions. Operations sees systems, processes. General sees the cross-domain picture. None of these are dashboards. They are pre-read summaries that mean I and the system both walk into the day already briefed. This is the Stulberg layer.
A RESOLVER.md at the root, one row per skill or scheduled task, with the rule that any new skill or task adds a row in the same change. This is the Tan layer.
An entity system for people, deals, projects and accounts. 524 people. 355 companies. 66 active deals. Every person who matters to the businesses has a markdown file. Every active deal does. Every project does. The wiki cross-references entities so that a brief about a deal automatically pulls in the contacts, the company, the recent activity, the open questions.
A daily inbox triage that runs across email, Granola transcripts and Slack-equivalent channels three times a day. It routes, drafts replies, flags decisions, files signals. Drafts only. No autosend. That rule is hard, and it stays hard (for now).
A nightly digest that distils the day into one page in plain English, files outcomes back into the entity system, and updates the live wiki articles. This is the “answer is also knowledge” loop made operational.
Filing rules and a weekly filing-lint pass that flags violations. Tan’s discipline lifted into my own substrate.
What is working. The brief-once-and-it-lasts effect is real. Stulberg’s specific phrase about not having to re-explain who Taylor is on the team, that detail repeated across every meeting, every prompt, every chat, that is the daily lived experience now. The model walks in primed. I do not retype context.
The compounding is also real. The wiki today is materially better than it was when I started, not because I edited it but because the routine answered questions and filed answers back in. Compound loops and flywheels are the most powerful force in business.
What is not working yet. The system still over-produces. There are too many syncs running, too many briefings being generated when the underlying data did not change. Some of the role briefings repeat themselves across days because nothing genuinely shifted. The next sweep is to make the system idle when there is nothing to say, and surface only the deltas.
The other unfinished work is the human-in-the-loop layer. Drafts get written. Approval queues are not yet a clean workflow. I am bouncing between three different surfaces depending on the action type. That needs collapsing into one.
What is next. Three things on the roadmap. First, a Glass-style shared skills library so the substrate I have built for myself can be installed inside other businesses without being a custom build every time. Second, a delta-aware sync layer so the system goes quiet when nothing has changed. Third, a small set of role-shaped entry points so someone new to the system can sit down, find the briefing that matches their job, and start contributing without reading the architecture documents first. Your average employee is not interested in the architecture, they just want it to work. Stulberg’s strategy partner is the test case I keep in mind.
Part 3: Inside companies
What is hard about building this inside a company
I have been installing pieces of this inside a variety of businesses since the start of the year through Claude Teams engagements. The patterns repeat and the patterns are the lesson. Most of the technical architecture I have just described is the easy part. The hard parts are not in the system. They are in the company.
The first hurdle is context capture. Every business already has a Company Brain. It is just scattered. It lives in Slack threads, email replies, half-written docs, the head of one operations lead, three abandoned Notion pages, a private Google Doc no one else can find, and the unwritten “how we actually do this” that lives in the implicit hand-off between two senior people. The work is not building a brain. The work is consolidating, structuring and routing what is already there. That is months of work, not an afternoon. Most installs underestimate this hugely. The technical layer takes two weeks. The capture habit takes a quarter.
Check Jaya Gupta’s December X article for more on this context capture layer.
The second hurdle is what should be written and what should not. Not every Slack message belongs in the brain. Not every email. Not every meeting. The signal-to-noise problem is real and gets worse the more you write. The discipline that has held up best for me, and the one I push hardest in client engagements, is the question “would I want my future self, or a colleague, to find this in three months”. Decisions yes. Reasons-for-decisions yes. Standard operating procedures yes. The “how we actually do X here” that lives unwritten in senior people’s heads, absolutely yes. Hot-takes in passing, in-jokes, half-finished thoughts, no. The brain is not a backup of every conversation. It is the curated layer underneath. Karpathy’s point about the answer being knowledge depends on the answer being worth keeping.
The third hurdle is fear. People are scared of two things at once. They are scared the system will replace them, and they are scared of being seen to be slow on the uptake if they do not engage with it. Both fears stop adoption. The teams that move past it are the ones where leadership says clearly and repeatedly that the brain exists to make people more leveraged, not redundant, and where the first wins are visible to the people doing the work, not just to leadership. Stulberg’s strategy partner is the canonical answer here. She is more leveraged because of the brain, not less. That is the story that has to land internally. If it does not, the brain stays empty.
The fourth hurdle is hardware. This sounds boring and it is the thing that kills more installs than any of the rest. Most companies run on a mix of personal devices, locked-down laptops, mobile-first behaviour from sales teams, and a security policy that was written in 2019 and never updated. A repository-based brain assumes everyone has a machine that can install Claude Code or Cursor or the equivalent, run scheduled tasks, and write to a git repo. That assumption is wrong roughly half the time. The pragmatic answer is to start with a sub-team that does have the hardware (usually whoever owns developer tooling already), prove value, and then negotiate the device and security questions with IT once the brain has shown its worth. Trying to fight that battle on day one ends the conversation.
The fifth hurdle is the big-brother optics. The same week I am installing a Company Brain in a business, the same business is reading articles about “AI surveillance” and “agents reading your emails”. The optics matter. The substance matters more, but the optics drive adoption. Three things have helped. First, drafts only. The system never sends. A human always approves. That alone removes most of the surveillance fear because nothing leaves the building without a person clicking go. Second, transparency about what is captured. The brain is a repo. Anyone with access can read it, see what is in it, and challenge what should not be. There is no hidden index, no shadow database. Third, opt-in by team. The brain is not pushed onto the org. It grows where it earns trust. The teams that benefit recruit other teams.
The sixth hurdle is the prize. Once the brain exists, agents become useful. Not before. Almost every “AI agent failed in production” story I have looked into traces back to the same root cause: the agent had no substrate to operate on. The model was fine. The context was missing. YC’s framing in the RFS is exactly right. The Company Brain is the missing layer between raw company data and reliable AI automation. The hurdle is that you cannot get to the prize without doing the unglamorous work first.
Want the next one? I send a Saturday letter to operators thinking through Company Brains, Leanpreneur economics and how to run leveraged businesses. Subscribe here.
Why this set-up is antifragile
There is a property of this architecture that is worth its own section, because it is the reason I am willing to keep investing in it under any plausible future.
This set-up is antifragile. The actuators (the AI tooling) are interchangeable. The brain (the flight computer) is owned, sovereign and portable.
Models churn every few months. Claude beats GPT this quarter. A new Anthropic frontier model will land. Gemini will leapfrog. A startup with a different architecture will come out of nowhere. None of that should bend the system. The actuators are downstream. You change which engine is bolted to the airframe. The airframe stays.
The market churns too. SaaS tools rise and fall. Vendors reprice, deprecate features, get acquired and dismantled. If your operational memory lives inside Notion, or Confluence, or a startup chatbot’s RAG layer, you are renting your business memory from someone whose interests are not yours. When they change terms or shut down, you lose the substrate. That is the opposite of antifragile. That is fragile by design.
A markdown brain in a git repository on hardware you control is portable on purpose. You can run it through any model. You can move it between machines. You can take it with you when you sell the business. It cannot be deprecated by a vendor decision. The volatility in the AI market makes a substrate like this more valuable, not less. Every model release is an opportunity to upgrade the engine. Every vendor wobble is a confirmation of the build-not-rent decision. The system feeds on the chaos around it. That is what antifragile means in practice.
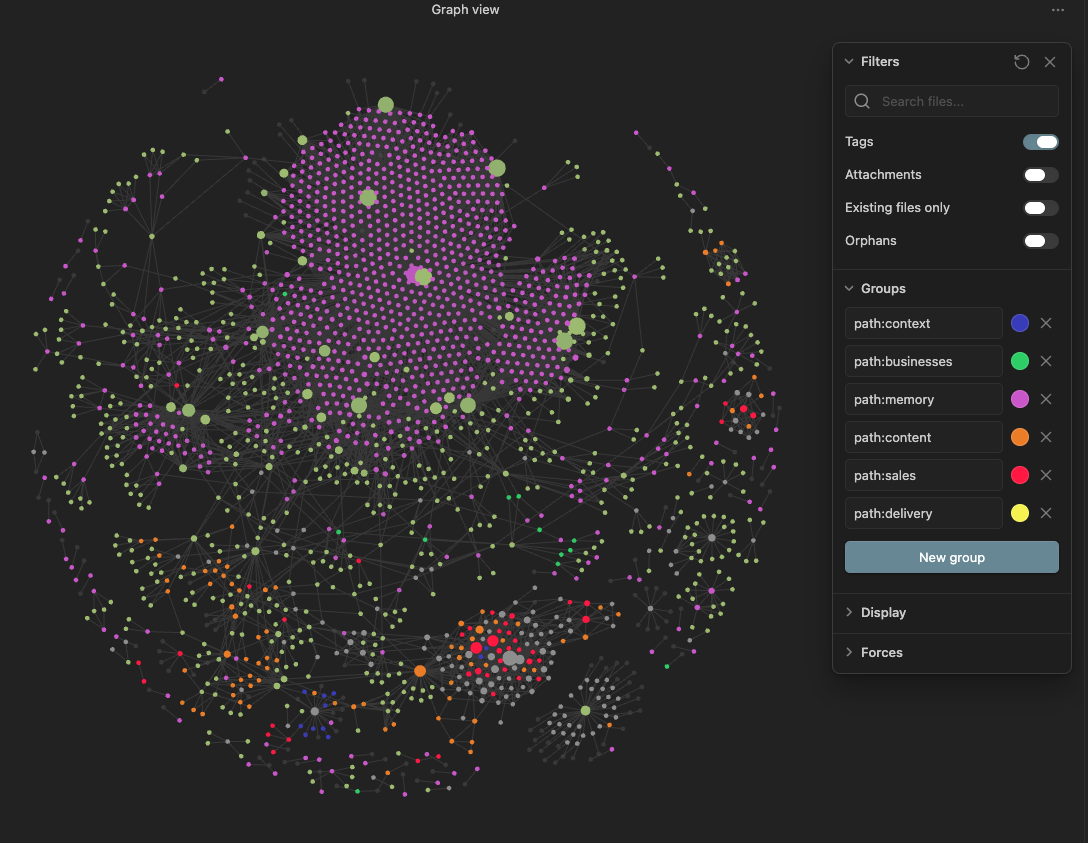
The image above is a snapshot of the AFCS knowledge graph rendered in Obsidian. Every node is a markdown file. Every line is a backlink. The cluster on one side is the wiki. The cluster on the other is the entity system. The bridges between them are the cross-references that compound. None of this lives in a SaaS database. None of it depends on Claude continuing to exist tomorrow. If Anthropic shut down overnight, the graph would still be here, the markdown would still be here, and I would point a different model at it on Tuesday.
That is the bet I am making with the substrate. It is the bet every builder in this piece is making in their own way. Karpathy’s wiki, Tan’s GBrain, Stulberg’s repo, Ramp’s Glass. All of them sit above an exchangeable model layer and below the human deciding what to keep. That is where the durable value lives.
What you should do about it
If you run a business of any size, the practical move is the same.
Stop optimising your tool stack. Start building your substrate.
Pick a folder. Pick a repo. Pick the simplest possible structure. A CLAUDE.md (or AGENTS.md) at the root that lists who is on the team, where the key channels are, and how the folder is organised. A docs index. A skills folder. A small set of role-specific briefings. A discipline of writing things back into it.
Do not buy a product for this yet. The tools that exist today are mostly chat-on-top-of-documents, which is the thing every builder I named above explicitly rejected. Notion is not a Company Brain. A Confluence wiki is not a Company Brain. Even your favourite RAG-based search is not a Company Brain. None of those were designed to be agent-executable. They were designed to be human-readable. The brain you need is both.
Bring one non-technical person into the loop early. Stulberg’s leading proof point was not a metric. It was a person. A strategy partner who had never opened GitHub making daily pull requests. If your wiki is only used by engineers, you have a docs system. If your wiki is used by everyone, you have an operating layer. The difference is enormous.
Treat skills as the unit. Every recurring decision, every standard operating procedure, every “how we do X here” lives as a skill in the repo, not as a folder of meeting notes. Garry Tan’s check-resolvable audit is not a quirky power user move. It is the equivalent of a quarterly review for your operating system. Things drift. Capabilities go dark. The audit catches it.
Move slowly enough that the structure stays clean. Stulberg said it took her team 1,500 hours of iteration and they are still adjusting daily. The right speed is not as fast as you can. The right speed is sustainable enough that the file in the repo a year from now is still the file you want.
The bigger picture
There is a subtle point in YC’s framing that is worth pulling out. They are not asking founders to build a smarter model. They are asking founders to build the system that makes models useful inside real companies. The investable thing is the substrate, not the inference. The full Summer 2026 RFS is here and the Company Brain section sits alongside agriculture robotics, lunar manufacturing and semiconductor supply chain. That is the company it is keeping.
That is also the operator move. Most leverage is no longer in the tool. Most leverage is in the layer underneath. The wiki is where your judgment lives. The skills are where your standards live. The resolver is where your routing lives. The model is the easy bit. The model is the engine. The substrate is the airframe.
Karpathy posted the seed. Tan formalised the operating discipline. Stulberg made it work for a non-technical partner. Ramp scaled it across a company. YC named it. I am still building mine. The hurdles inside companies are real and the work is unglamorous. The opportunity is not to be the next person to get to the architecture. It is to start building yours this week, and to take the adoption work as seriously as the technical work.
If you want to see a working version, the full architecture of mine is in How I Built a Second Brain That Builds Itself. If you want to think out loud about what yours should look like, that is most of what we work on inside the Leanpreneur Community, and most of what I do in coaching sessions and project engagements.
The Company Brain is not the next tool to buy. It is the next system to build. The people who build theirs first, and who do the unglamorous adoption work alongside the technical work, will run businesses that look very different from the people who keep buying tools that sit above it.
Enjoyed this? Join the newsletter.
One email a week. What I'm building, learning, and what's actually working. No fluff.
Free. Unsubscribe anytime.